实现
下面将使用Scheme语言来实现“无重复字符的最长子串”,即,对于字符串"abbabcx",其最长无重复字符的子串为"abcx",长度4,详细描述可访问https://leetcode-cn.com/problems/longest-substring-without-repeating-characters/
(let*
(
[s "abbabcx"]
[arr-index 0]
[ans 0]
[d -1]
[vec (make-vector 128 -1)]
[keep-last-position (lambda (c pos-in-s) (vector-set! vec c pos-in-s))]
[scan (lambda (c pos-in-s)
(let*
([previous-pos (vector-ref vec c)] [len 0])
(begin
(when
(and (>= previous-pos 0) (> previous-pos d))
(set! d previous-pos)
)
(set! len (- pos-in-s d))
(keep-last-position c pos-in-s)
(when (> len ans) (set! ans len))
)
)
)]
)
(
string-for-each
(lambda (e) (scan (char->integer e) arr-index) (set! arr-index (+ arr-index 1)))
s
)
ans
)
实现的思路为:
由于字符可以有ASCII码表示,故可以用一个长度为128的向量vec来保存每个字符在给定的字符串中出现的最后一次的位置。维护一个变量d来记录最近一次出现重复的字符的起始位置。 如果:
- 判断某字符是否重复: 1.1 某字符第一次出现,执行第2步 1.2 某字符非第一次出现,如果该字符上次出现的位置,在d之后,则将d设置为该字符上次出现的位置。由于之前的最大长度已经由ans保存,所以只需要计算剩下的子串的长度能不能大于ans,这就是为什么d记录最近一次出现重复的字符串的起始位置就好了
- 计算当前位置和d的长度len
- 保存其位置到vec
- 如果len大于ans,改变ans为len
这种实现只需遍历一遍就可以计算出结果,性能非常棒。当然暴力计算或者滑动窗口也可以实现该功能,只是需要多次遍历,性能比不上。
概要分析
上文说到性能问题,拿点数据出来证明一下吧。
将上面的代码稍微改造一下,作为一个definition,并保存在longest_substr.ss文件中,
(define longest-substr
(lambda (str)
(let*
(
[s str]
[arr-index 0]
[ans 0]
[d -1]
[vec (make-vector 128 -1)]
[keep-last-position (lambda (c pos-in-s) (vector-set! vec c pos-in-s))]
[scan (lambda (c pos-in-s)
(let*
([previous-pos (vector-ref vec c)] [len 0])
(begin
(when
(and (>= previous-pos 0) (> previous-pos d))
(set! d previous-pos)
)
(set! len (- pos-in-s d))
(keep-last-position c pos-in-s)
(when (> len ans) (set! ans len))
)
)
)]
)
(
string-for-each
(lambda (e) (scan (char->integer e) arr-index) (set! arr-index (+ arr-index 1)))
s
)
ans
)
)
)
Chez Scheme提供了一个概要分析工具,非常好用,来试用一下:
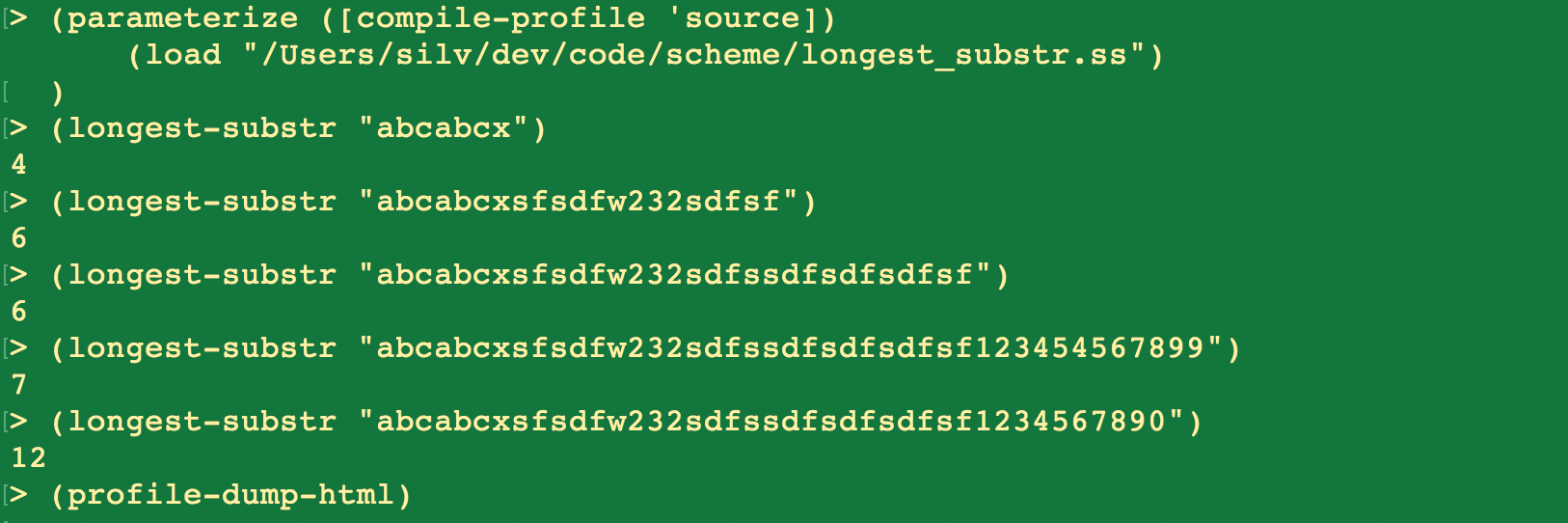
生成的html可以非常直观的看到该函数的执行情况

字符串越长,执行次数越多,执行时间是多少呢?选一个上面例子中最长的字符串来看看:
> (time (longest-substr "abcabcxsfsdfw232sdfssdfsdfsdfsf1234567890"))
(time (longest-substr "abcabcxsfsdfw232sdfssdfsdfsdfsf1234567890"))
no collections
0.000003672s elapsed cpu time
0.000002000s elapsed real time
1792 bytes allocated
12
>
消耗的CPU时间0.000003672s,可以说非常短了,且分配的内存仅仅1792个字节。超乎寻常的性能,我想应该有两个方面原因:
- 算法
- Scheme 和 Chez Scheme

